|
VM2D
1.12
Vortex methods for 2D flows simulation
|
|
VM2D
1.12
Vortex methods for 2D flows simulation
|
Classes | |
| struct | CudaCalcGab |
| struct | CudaSorter |
Functions | |
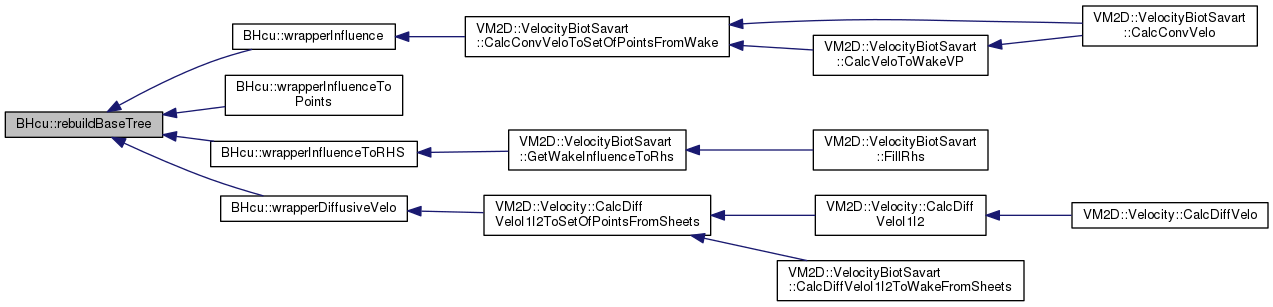
| void | rebuildBaseTree (CUDApointers &ptrs, const int nbodies, const realVortex *vtxl, int nnodes, int order, double *timing) |
| double | memoryAllocate (CUDApointers &ptrs, int nnodes, int nbodies, int nbodiesOld, int blocks, int order) |
| double | wrapperInfluence (const realVortex *vtxl, realPoint *vell, real *epsastl, CUDApointers &ptrs, int nbodies, double *timing, real eps, real theta, size_t &nbodiesOld, int nbodiesUp, int order, size_t nAfls, size_t *nVtxs, double **ptrVtxs) |
| double | wrapperInfluenceToPoints (const realVortex *vtxl, const realVortex *pointsl, realPoint *vell, real *epsastl, CUDApointers &ptrs, bool rebuild, int nbodies, int npoints, double *timing, real eps, real theta, size_t &nbodiesOld, int nbodiesUp, int order, size_t nAfls, size_t *nVtxs, double **ptrVtxs) |
| npoints - ����� ����� ���������� More... | |
| double | wrapperInfluenceToRHS (const realVortex *dev_ptr_vt, const double *dev_ptr_pt, double *dev_ptr_rhs, double *dev_ptr_rhslin, CUDApointers &ptrs, bool rebuild, int nvt, int nTotPan, double *timingsToRHS, double theta, size_t &nbodiesOld, int nbodiesUp, int order, int scheme) |
| double | wrapperDiffusiveVelo (const realVortex *vtxl, real *i1l, realPoint *i2l, real *epsastl, CUDApointers &ptrs, bool rebuild, int nbodies, double *timing, real eps, real theta, size_t &nbodiesOld, int nbodiesUp, int order, size_t nAfls, size_t *nVtxs, double **ptrVtxs) |
Variables | |
| const real | IDPI = (real)0.15915494309189534 |
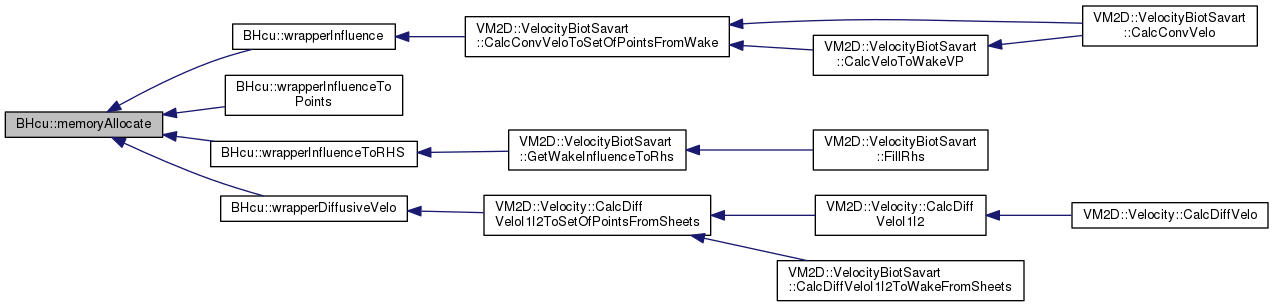
| double BHcu::memoryAllocate | ( | CUDApointers & | ptrs, |
| int | nnodes, | ||
| int | nbodies, | ||
| int | nbodiesOld, | ||
| int | blocks, | ||
| int | order | ||
| ) |
For Morton tree
For MortonTree
Definition at line 193 of file wrapper.cpp.
| void BHcu::rebuildBaseTree | ( | CUDApointers & | ptrs, |
| const int | nbodies, | ||
| const realVortex * | vtxl, | ||
| int | nnodes, | ||
| int | order, | ||
| double * | timing | ||
| ) |
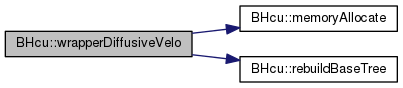
| double BHcu::wrapperDiffusiveVelo | ( | const realVortex * | vtxl, |
| real * | i1l, | ||
| realPoint * | i2l, | ||
| real * | epsastl, | ||
| CUDApointers & | ptrs, | ||
| bool | rebuild, | ||
| int | nbodies, | ||
| double * | timing, | ||
| real | eps, | ||
| real | theta, | ||
| size_t & | nbodiesOld, | ||
| int | nbodiesUp, | ||
| int | order, | ||
| size_t | nAfls, | ||
| size_t * | nVtxs, | ||
| double ** | ptrVtxs | ||
| ) |
Definition at line 497 of file wrapper.cpp.

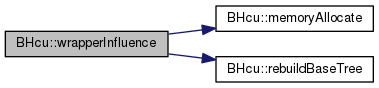
| double BHcu::wrapperInfluence | ( | const realVortex * | vtxl, |
| realPoint * | vell, | ||
| real * | epsastl, | ||
| CUDApointers & | ptrs, | ||
| int | nbodies, | ||
| double * | timing, | ||
| real | eps, | ||
| real | theta, | ||
| size_t & | nbodiesOld, | ||
| int | nbodiesUp, | ||
| int | order, | ||
| size_t | nAfls, | ||
| size_t * | nVtxs, | ||
| double ** | ptrVtxs | ||
| ) |
| vtxl |
��������� �� ����� �� GPU
| vell |
��������� �� ������ ����������� ��������� �� GPU
| epsastl |
��������� �� ������ eps* �� GPU
| ptrs |
��������� ����������, ����������� � ������
| nbodies |
����� ������
| timing |
��������� �� 7-���������� ������ ��� ������� ������� ��� �������� ������
| eps |
eps
| theta |
theta
| nbodiesOld |
����� ������, ��� ������� ���� �������� ������ �� ������� ����
| nbodiesUp |
����� ������ (������ ������), ��� ������� ��������� ������ �� ������� ����
| order |
order
| nAfls |
����� ��������
| nVtxs |
��������� �� ������ �� ����� ������, ��������������� �� ��������
| ptrVtxs |
��������� �� ���
Definition at line 280 of file wrapper.cpp.

| double BHcu::wrapperInfluenceToPoints | ( | const realVortex * | vtxl, |
| const realVortex * | pointsl, | ||
| realPoint * | vell, | ||
| real * | epsastl, | ||
| CUDApointers & | ptrs, | ||
| bool | rebuild, | ||
| int | nbodies, | ||
| int | npoints, | ||
| double * | timing, | ||
| real | eps, | ||
| real | theta, | ||
| size_t & | nbodiesOld, | ||
| int | nbodiesUp, | ||
| int | order, | ||
| size_t | nAfls, | ||
| size_t * | nVtxs, | ||
| double ** | ptrVtxs | ||
| ) |
npoints - ����� ����� ����������
Definition at line 340 of file wrapper.cpp.
| double BHcu::wrapperInfluenceToRHS | ( | const realVortex * | dev_ptr_vt, |
| const double * | dev_ptr_pt, | ||
| double * | dev_ptr_rhs, | ||
| double * | dev_ptr_rhslin, | ||
| CUDApointers & | ptrs, | ||
| bool | rebuild, | ||
| int | nvt, | ||
| int | nTotPan, | ||
| double * | timingsToRHS, | ||
| double | theta, | ||
| size_t & | nbodiesOld, | ||
| int | nbodiesUp, | ||
| int | order, | ||
| int | scheme | ||
| ) |
Definition at line 410 of file wrapper.cpp.

| const real BHcu::IDPI = (real)0.15915494309189534 |
Definition at line 95 of file wrapper.cpp.
 1.8.11
1.8.11